Type experimental
Namespace tensorflow.compat.v2.train.experimental
Methods
- disable_mixed_precision_graph_rewrite
- disable_mixed_precision_graph_rewrite_dyn
- enable_mixed_precision_graph_rewrite
- enable_mixed_precision_graph_rewrite
- enable_mixed_precision_graph_rewrite
- enable_mixed_precision_graph_rewrite
- enable_mixed_precision_graph_rewrite_dyn
Properties
Public static methods
void disable_mixed_precision_graph_rewrite()
Disables the mixed precision graph rewrite. After this is called, the mixed precision graph rewrite will no longer run for
new Sessions, and so float32 operations will no longer be converted to float16
in such Sessions. However, any existing Sessions will continue to have the
graph rewrite enabled if they were created after
`enable_mixed_precision_graph_rewrite` was called but before
`disable_mixed_precision_graph_rewrite` was called. This does not undo the effects of loss scaling. Any optimizers wrapped with a
LossScaleOptimizer will continue to do loss scaling, although this loss
scaling will no longer be useful if the optimizer is used in new Sessions, as
the graph rewrite no longer converts the graph to use float16. This function is useful for unit testing. A unit tests can test using the
mixed precision graph rewrite, then disable it so future unit tests continue
using float32. If this is done, unit tests should not share a single session,
as `enable_mixed_precision_graph_rewrite` and
`disable_mixed_precision_graph_rewrite` have no effect on existing sessions.
object disable_mixed_precision_graph_rewrite_dyn()
Disables the mixed precision graph rewrite. After this is called, the mixed precision graph rewrite will no longer run for
new Sessions, and so float32 operations will no longer be converted to float16
in such Sessions. However, any existing Sessions will continue to have the
graph rewrite enabled if they were created after
`enable_mixed_precision_graph_rewrite` was called but before
`disable_mixed_precision_graph_rewrite` was called. This does not undo the effects of loss scaling. Any optimizers wrapped with a
LossScaleOptimizer will continue to do loss scaling, although this loss
scaling will no longer be useful if the optimizer is used in new Sessions, as
the graph rewrite no longer converts the graph to use float16. This function is useful for unit testing. A unit tests can test using the
mixed precision graph rewrite, then disable it so future unit tests continue
using float32. If this is done, unit tests should not share a single session,
as `enable_mixed_precision_graph_rewrite` and
`disable_mixed_precision_graph_rewrite` have no effect on existing sessions.
object enable_mixed_precision_graph_rewrite(Trackable opt, double loss_scale)
Enable mixed precision via a graph rewrite. Mixed precision is the use of both float32 and float16 data types when
training a model to improve performance. This is achieved via a graph rewrite
operation and a loss-scale optimizer. Performing arithmetic operations in float16 takes advantage of specialized
processing units, such as NVIDIA Tensor Cores for much higher arithmetic
throughput. However, due to the smaller representable range, performing the
entire training with float16 can result in gradient underflow, that is, small
gradient values becoming zeroes. Instead, performing only select arithmetic
operations in float16 results in higher throughput and decreased training
time when using compatible hardware accelerators while also reducing memory
usage, typically without sacrificing model accuracy. Note: While the mixed precision rewrite changes the datatype of various
layers throughout the model, the same accuracy reached in float32 is
expected. If a `NaN` gradient occurs with dynamic loss scaling, the model
update for that batch is skipped. In this case, the global step count is not
incremented, and the `LossScaleOptimizer` attempts to decrease the loss
scaling value to avoid `NaN` values in subsequent iterations. This approach
has been shown to achieve the same accuracy as float32 and, in most cases,
better training throughput. Example:
For a complete example showing the speed-up on training an image
classification task on CIFAR10, check out this
Colab notebook. Calling `enable_mixed_precision_graph_rewrite(opt)` enables the graph rewrite
operation before computing gradients. The function additionally returns an
`Optimizer`(`opt`) wrapped with a `LossScaleOptimizer`. This prevents
underflow in the float16 tensors during the backward pass. An optimizer of
type 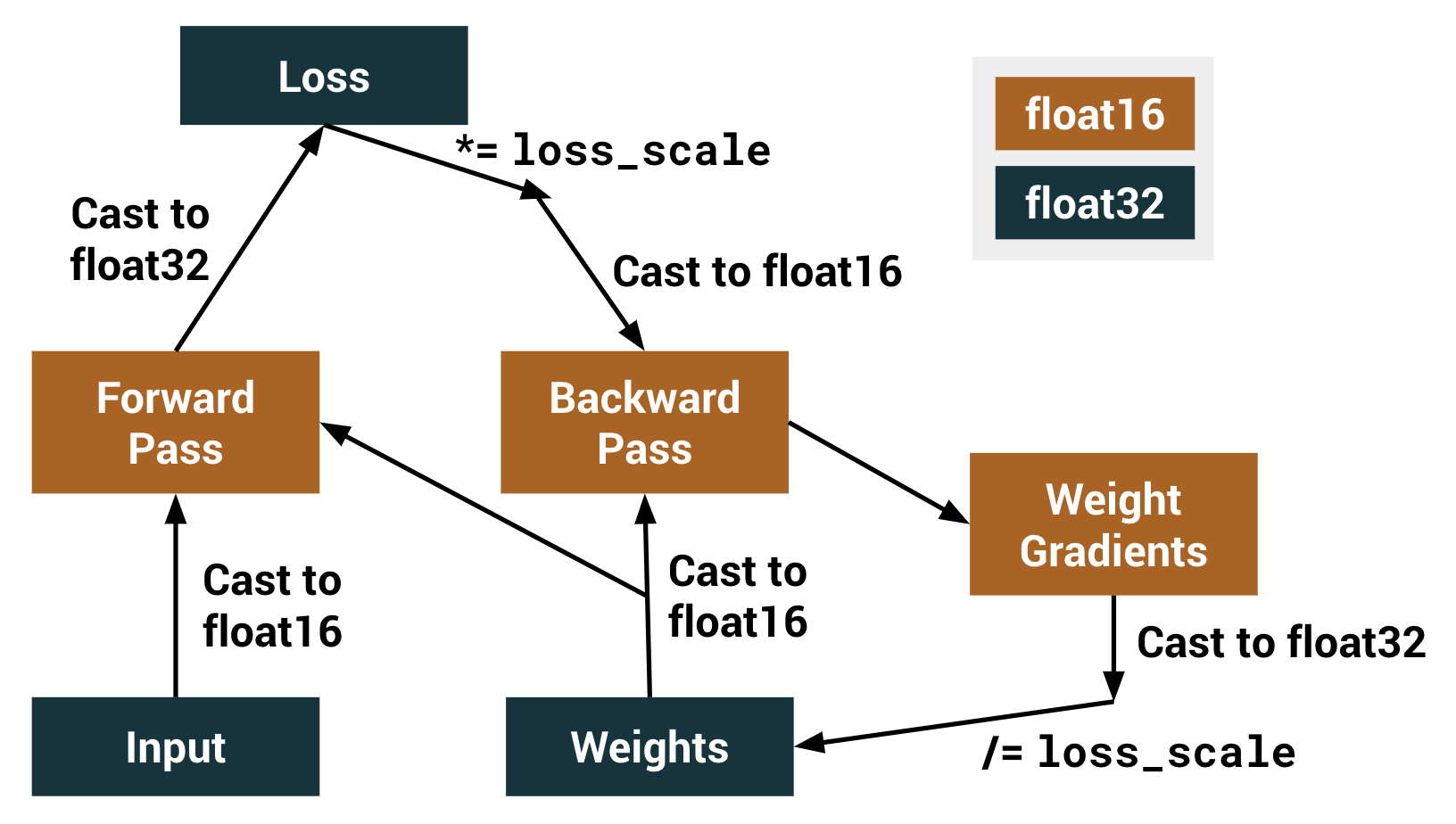 The graph rewrite operation changes the `dtype` of certain operations in the
graph from float32 to float16. There are several categories of operations
that are either included or excluded by this rewrite operation. The following
categories of Ops are defined inside corresponding functions under the class
`AutoMixedPrecisionLists` in
auto_mixed_precision_lists.h: * `ClearList`: Ops that do not have numerically significant adverse effects.
E.g. `ArgMax` and `Floor`.
* `WhiteList`: Ops that are considered numerically safe for execution in
float16, and thus are always converted. E.g. `Conv2D`.
* `BlackList`: Ops that are numerically unsafe to execute in float16 and
can negatively affect downstream nodes. E.g. `Softmax`.
* `GrayList`: Ops that are considered numerically safe for execution in
float16 unless downstream from a BlackList Op. E.g. `Add` and `AvgPool`. When this function is used, gradients should only be computed and applied
with the returned optimizer, either by calling `opt.minimize()` or
`opt.compute_gradients()` followed by `opt.apply_gradients()`.
Gradients should not be computed with
The graph rewrite operation changes the `dtype` of certain operations in the
graph from float32 to float16. There are several categories of operations
that are either included or excluded by this rewrite operation. The following
categories of Ops are defined inside corresponding functions under the class
`AutoMixedPrecisionLists` in
auto_mixed_precision_lists.h: * `ClearList`: Ops that do not have numerically significant adverse effects.
E.g. `ArgMax` and `Floor`.
* `WhiteList`: Ops that are considered numerically safe for execution in
float16, and thus are always converted. E.g. `Conv2D`.
* `BlackList`: Ops that are numerically unsafe to execute in float16 and
can negatively affect downstream nodes. E.g. `Softmax`.
* `GrayList`: Ops that are considered numerically safe for execution in
float16 unless downstream from a BlackList Op. E.g. `Add` and `AvgPool`. When this function is used, gradients should only be computed and applied
with the returned optimizer, either by calling `opt.minimize()` or
`opt.compute_gradients()` followed by `opt.apply_gradients()`.
Gradients should not be computed with
tf.train.Optimizer or tf.keras.optimizers.Optimizer must be passed
to this function, which will then be wrapped to use loss scaling. The graph rewrite operation changes the `dtype` of certain operations in the
graph from float32 to float16. There are several categories of operations
that are either included or excluded by this rewrite operation. The following
categories of Ops are defined inside corresponding functions under the class
`AutoMixedPrecisionLists` in
auto_mixed_precision_lists.h: * `ClearList`: Ops that do not have numerically significant adverse effects.
E.g. `ArgMax` and `Floor`.
* `WhiteList`: Ops that are considered numerically safe for execution in
float16, and thus are always converted. E.g. `Conv2D`.
* `BlackList`: Ops that are numerically unsafe to execute in float16 and
can negatively affect downstream nodes. E.g. `Softmax`.
* `GrayList`: Ops that are considered numerically safe for execution in
float16 unless downstream from a BlackList Op. E.g. `Add` and `AvgPool`. When this function is used, gradients should only be computed and applied
with the returned optimizer, either by calling `opt.minimize()` or
`opt.compute_gradients()` followed by `opt.apply_gradients()`.
Gradients should not be computed with tf.gradients or tf.GradientTape.
This is because the returned optimizer will apply loss scaling, and
tf.gradients or tf.GradientTape will not. If you do directly use
tf.gradients or tf.GradientTape, your model may not converge due to
float16 underflow problems. When eager execution is enabled, the mixed precision graph rewrite is only
enabled within tf.function, as outside tf.function, there is no graph. For NVIDIA GPUs with Tensor cores, as a general performance guide, dimensions
(such as batch size, input size, output size, and channel counts)
should be powers of two if under 256, or otherwise divisible by 8 if above
256. For more information, check out the
[NVIDIA Deep Learning Performance Guide](
https://docs.nvidia.com/deeplearning/sdk/dl-performance-guide/index.html). Currently, mixed precision is only enabled on NVIDIA Tensor Core GPUs with
Compute Capability 7.0 and above (Volta, Turing, or newer architectures). The
parts of the graph on CPUs and TPUs are untouched by the graph rewrite. TPU
support is coming soon. CPUs are not supported, as CPUs do not run float16
operations faster than float32 operations.
Parameters
-
Trackableopt - An instance of a
tf.keras.optimizers.Optimizeror atf.train.Optimizer. -
doubleloss_scale - Either an int/float, the string `"dynamic"`, or an instance of
a
tf.train.experimental.LossScale. The loss scale to use. It is recommended to keep this as its default value of `"dynamic"`, which will adjust the scaling automatically to prevent `Inf` or `NaN` values.
Returns
-
object - A version of `opt` that will use loss scaling to prevent underflow.
Show Example
model = tf.keras.models.Sequential([
...
]) opt = tf.keras.optimizers.SGD()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt) model.compile(loss="categorical_crossentropy",
optimizer=opt,
metrics=["accuracy"]) model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs)
object enable_mixed_precision_graph_rewrite(Trackable opt, string loss_scale)
Enable mixed precision via a graph rewrite. Mixed precision is the use of both float32 and float16 data types when
training a model to improve performance. This is achieved via a graph rewrite
operation and a loss-scale optimizer. Performing arithmetic operations in float16 takes advantage of specialized
processing units, such as NVIDIA Tensor Cores for much higher arithmetic
throughput. However, due to the smaller representable range, performing the
entire training with float16 can result in gradient underflow, that is, small
gradient values becoming zeroes. Instead, performing only select arithmetic
operations in float16 results in higher throughput and decreased training
time when using compatible hardware accelerators while also reducing memory
usage, typically without sacrificing model accuracy. Note: While the mixed precision rewrite changes the datatype of various
layers throughout the model, the same accuracy reached in float32 is
expected. If a `NaN` gradient occurs with dynamic loss scaling, the model
update for that batch is skipped. In this case, the global step count is not
incremented, and the `LossScaleOptimizer` attempts to decrease the loss
scaling value to avoid `NaN` values in subsequent iterations. This approach
has been shown to achieve the same accuracy as float32 and, in most cases,
better training throughput. Example:
For a complete example showing the speed-up on training an image
classification task on CIFAR10, check out this
Colab notebook. Calling `enable_mixed_precision_graph_rewrite(opt)` enables the graph rewrite
operation before computing gradients. The function additionally returns an
`Optimizer`(`opt`) wrapped with a `LossScaleOptimizer`. This prevents
underflow in the float16 tensors during the backward pass. An optimizer of
type The graph rewrite operation changes the `dtype` of certain operations in the
graph from float32 to float16. There are several categories of operations
that are either included or excluded by this rewrite operation. The following
categories of Ops are defined inside corresponding functions under the class
`AutoMixedPrecisionLists` in
auto_mixed_precision_lists.h: * `ClearList`: Ops that do not have numerically significant adverse effects.
E.g. `ArgMax` and `Floor`.
* `WhiteList`: Ops that are considered numerically safe for execution in
float16, and thus are always converted. E.g. `Conv2D`.
* `BlackList`: Ops that are numerically unsafe to execute in float16 and
can negatively affect downstream nodes. E.g. `Softmax`.
* `GrayList`: Ops that are considered numerically safe for execution in
float16 unless downstream from a BlackList Op. E.g. `Add` and `AvgPool`. When this function is used, gradients should only be computed and applied
with the returned optimizer, either by calling `opt.minimize()` or
`opt.compute_gradients()` followed by `opt.apply_gradients()`.
Gradients should not be computed with
tf.train.Optimizer or tf.keras.optimizers.Optimizer must be passed
to this function, which will then be wrapped to use loss scaling. The graph rewrite operation changes the `dtype` of certain operations in the
graph from float32 to float16. There are several categories of operations
that are either included or excluded by this rewrite operation. The following
categories of Ops are defined inside corresponding functions under the class
`AutoMixedPrecisionLists` in
auto_mixed_precision_lists.h: * `ClearList`: Ops that do not have numerically significant adverse effects.
E.g. `ArgMax` and `Floor`.
* `WhiteList`: Ops that are considered numerically safe for execution in
float16, and thus are always converted. E.g. `Conv2D`.
* `BlackList`: Ops that are numerically unsafe to execute in float16 and
can negatively affect downstream nodes. E.g. `Softmax`.
* `GrayList`: Ops that are considered numerically safe for execution in
float16 unless downstream from a BlackList Op. E.g. `Add` and `AvgPool`. When this function is used, gradients should only be computed and applied
with the returned optimizer, either by calling `opt.minimize()` or
`opt.compute_gradients()` followed by `opt.apply_gradients()`.
Gradients should not be computed with tf.gradients or tf.GradientTape.
This is because the returned optimizer will apply loss scaling, and
tf.gradients or tf.GradientTape will not. If you do directly use
tf.gradients or tf.GradientTape, your model may not converge due to
float16 underflow problems. When eager execution is enabled, the mixed precision graph rewrite is only
enabled within tf.function, as outside tf.function, there is no graph. For NVIDIA GPUs with Tensor cores, as a general performance guide, dimensions
(such as batch size, input size, output size, and channel counts)
should be powers of two if under 256, or otherwise divisible by 8 if above
256. For more information, check out the
[NVIDIA Deep Learning Performance Guide](
https://docs.nvidia.com/deeplearning/sdk/dl-performance-guide/index.html). Currently, mixed precision is only enabled on NVIDIA Tensor Core GPUs with
Compute Capability 7.0 and above (Volta, Turing, or newer architectures). The
parts of the graph on CPUs and TPUs are untouched by the graph rewrite. TPU
support is coming soon. CPUs are not supported, as CPUs do not run float16
operations faster than float32 operations.
Parameters
-
Trackableopt - An instance of a
tf.keras.optimizers.Optimizeror atf.train.Optimizer. -
stringloss_scale - Either an int/float, the string `"dynamic"`, or an instance of
a
tf.train.experimental.LossScale. The loss scale to use. It is recommended to keep this as its default value of `"dynamic"`, which will adjust the scaling automatically to prevent `Inf` or `NaN` values.
Returns
-
object - A version of `opt` that will use loss scaling to prevent underflow.
Show Example
model = tf.keras.models.Sequential([
...
]) opt = tf.keras.optimizers.SGD()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt) model.compile(loss="categorical_crossentropy",
optimizer=opt,
metrics=["accuracy"]) model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs)
object enable_mixed_precision_graph_rewrite(int opt, double loss_scale)
Enable mixed precision via a graph rewrite. Mixed precision is the use of both float32 and float16 data types when
training a model to improve performance. This is achieved via a graph rewrite
operation and a loss-scale optimizer. Performing arithmetic operations in float16 takes advantage of specialized
processing units, such as NVIDIA Tensor Cores for much higher arithmetic
throughput. However, due to the smaller representable range, performing the
entire training with float16 can result in gradient underflow, that is, small
gradient values becoming zeroes. Instead, performing only select arithmetic
operations in float16 results in higher throughput and decreased training
time when using compatible hardware accelerators while also reducing memory
usage, typically without sacrificing model accuracy. Note: While the mixed precision rewrite changes the datatype of various
layers throughout the model, the same accuracy reached in float32 is
expected. If a `NaN` gradient occurs with dynamic loss scaling, the model
update for that batch is skipped. In this case, the global step count is not
incremented, and the `LossScaleOptimizer` attempts to decrease the loss
scaling value to avoid `NaN` values in subsequent iterations. This approach
has been shown to achieve the same accuracy as float32 and, in most cases,
better training throughput. Example:
For a complete example showing the speed-up on training an image
classification task on CIFAR10, check out this
Colab notebook. Calling `enable_mixed_precision_graph_rewrite(opt)` enables the graph rewrite
operation before computing gradients. The function additionally returns an
`Optimizer`(`opt`) wrapped with a `LossScaleOptimizer`. This prevents
underflow in the float16 tensors during the backward pass. An optimizer of
type The graph rewrite operation changes the `dtype` of certain operations in the
graph from float32 to float16. There are several categories of operations
that are either included or excluded by this rewrite operation. The following
categories of Ops are defined inside corresponding functions under the class
`AutoMixedPrecisionLists` in
auto_mixed_precision_lists.h: * `ClearList`: Ops that do not have numerically significant adverse effects.
E.g. `ArgMax` and `Floor`.
* `WhiteList`: Ops that are considered numerically safe for execution in
float16, and thus are always converted. E.g. `Conv2D`.
* `BlackList`: Ops that are numerically unsafe to execute in float16 and
can negatively affect downstream nodes. E.g. `Softmax`.
* `GrayList`: Ops that are considered numerically safe for execution in
float16 unless downstream from a BlackList Op. E.g. `Add` and `AvgPool`. When this function is used, gradients should only be computed and applied
with the returned optimizer, either by calling `opt.minimize()` or
`opt.compute_gradients()` followed by `opt.apply_gradients()`.
Gradients should not be computed with
tf.train.Optimizer or tf.keras.optimizers.Optimizer must be passed
to this function, which will then be wrapped to use loss scaling. The graph rewrite operation changes the `dtype` of certain operations in the
graph from float32 to float16. There are several categories of operations
that are either included or excluded by this rewrite operation. The following
categories of Ops are defined inside corresponding functions under the class
`AutoMixedPrecisionLists` in
auto_mixed_precision_lists.h: * `ClearList`: Ops that do not have numerically significant adverse effects.
E.g. `ArgMax` and `Floor`.
* `WhiteList`: Ops that are considered numerically safe for execution in
float16, and thus are always converted. E.g. `Conv2D`.
* `BlackList`: Ops that are numerically unsafe to execute in float16 and
can negatively affect downstream nodes. E.g. `Softmax`.
* `GrayList`: Ops that are considered numerically safe for execution in
float16 unless downstream from a BlackList Op. E.g. `Add` and `AvgPool`. When this function is used, gradients should only be computed and applied
with the returned optimizer, either by calling `opt.minimize()` or
`opt.compute_gradients()` followed by `opt.apply_gradients()`.
Gradients should not be computed with tf.gradients or tf.GradientTape.
This is because the returned optimizer will apply loss scaling, and
tf.gradients or tf.GradientTape will not. If you do directly use
tf.gradients or tf.GradientTape, your model may not converge due to
float16 underflow problems. When eager execution is enabled, the mixed precision graph rewrite is only
enabled within tf.function, as outside tf.function, there is no graph. For NVIDIA GPUs with Tensor cores, as a general performance guide, dimensions
(such as batch size, input size, output size, and channel counts)
should be powers of two if under 256, or otherwise divisible by 8 if above
256. For more information, check out the
[NVIDIA Deep Learning Performance Guide](
https://docs.nvidia.com/deeplearning/sdk/dl-performance-guide/index.html). Currently, mixed precision is only enabled on NVIDIA Tensor Core GPUs with
Compute Capability 7.0 and above (Volta, Turing, or newer architectures). The
parts of the graph on CPUs and TPUs are untouched by the graph rewrite. TPU
support is coming soon. CPUs are not supported, as CPUs do not run float16
operations faster than float32 operations.
Parameters
-
intopt - An instance of a
tf.keras.optimizers.Optimizeror atf.train.Optimizer. -
doubleloss_scale - Either an int/float, the string `"dynamic"`, or an instance of
a
tf.train.experimental.LossScale. The loss scale to use. It is recommended to keep this as its default value of `"dynamic"`, which will adjust the scaling automatically to prevent `Inf` or `NaN` values.
Returns
-
object - A version of `opt` that will use loss scaling to prevent underflow.
Show Example
model = tf.keras.models.Sequential([
...
]) opt = tf.keras.optimizers.SGD()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt) model.compile(loss="categorical_crossentropy",
optimizer=opt,
metrics=["accuracy"]) model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs)
object enable_mixed_precision_graph_rewrite(int opt, string loss_scale)
Enable mixed precision via a graph rewrite. Mixed precision is the use of both float32 and float16 data types when
training a model to improve performance. This is achieved via a graph rewrite
operation and a loss-scale optimizer. Performing arithmetic operations in float16 takes advantage of specialized
processing units, such as NVIDIA Tensor Cores for much higher arithmetic
throughput. However, due to the smaller representable range, performing the
entire training with float16 can result in gradient underflow, that is, small
gradient values becoming zeroes. Instead, performing only select arithmetic
operations in float16 results in higher throughput and decreased training
time when using compatible hardware accelerators while also reducing memory
usage, typically without sacrificing model accuracy. Note: While the mixed precision rewrite changes the datatype of various
layers throughout the model, the same accuracy reached in float32 is
expected. If a `NaN` gradient occurs with dynamic loss scaling, the model
update for that batch is skipped. In this case, the global step count is not
incremented, and the `LossScaleOptimizer` attempts to decrease the loss
scaling value to avoid `NaN` values in subsequent iterations. This approach
has been shown to achieve the same accuracy as float32 and, in most cases,
better training throughput. Example:
For a complete example showing the speed-up on training an image
classification task on CIFAR10, check out this
Colab notebook. Calling `enable_mixed_precision_graph_rewrite(opt)` enables the graph rewrite
operation before computing gradients. The function additionally returns an
`Optimizer`(`opt`) wrapped with a `LossScaleOptimizer`. This prevents
underflow in the float16 tensors during the backward pass. An optimizer of
type The graph rewrite operation changes the `dtype` of certain operations in the
graph from float32 to float16. There are several categories of operations
that are either included or excluded by this rewrite operation. The following
categories of Ops are defined inside corresponding functions under the class
`AutoMixedPrecisionLists` in
auto_mixed_precision_lists.h: * `ClearList`: Ops that do not have numerically significant adverse effects.
E.g. `ArgMax` and `Floor`.
* `WhiteList`: Ops that are considered numerically safe for execution in
float16, and thus are always converted. E.g. `Conv2D`.
* `BlackList`: Ops that are numerically unsafe to execute in float16 and
can negatively affect downstream nodes. E.g. `Softmax`.
* `GrayList`: Ops that are considered numerically safe for execution in
float16 unless downstream from a BlackList Op. E.g. `Add` and `AvgPool`. When this function is used, gradients should only be computed and applied
with the returned optimizer, either by calling `opt.minimize()` or
`opt.compute_gradients()` followed by `opt.apply_gradients()`.
Gradients should not be computed with
tf.train.Optimizer or tf.keras.optimizers.Optimizer must be passed
to this function, which will then be wrapped to use loss scaling. The graph rewrite operation changes the `dtype` of certain operations in the
graph from float32 to float16. There are several categories of operations
that are either included or excluded by this rewrite operation. The following
categories of Ops are defined inside corresponding functions under the class
`AutoMixedPrecisionLists` in
auto_mixed_precision_lists.h: * `ClearList`: Ops that do not have numerically significant adverse effects.
E.g. `ArgMax` and `Floor`.
* `WhiteList`: Ops that are considered numerically safe for execution in
float16, and thus are always converted. E.g. `Conv2D`.
* `BlackList`: Ops that are numerically unsafe to execute in float16 and
can negatively affect downstream nodes. E.g. `Softmax`.
* `GrayList`: Ops that are considered numerically safe for execution in
float16 unless downstream from a BlackList Op. E.g. `Add` and `AvgPool`. When this function is used, gradients should only be computed and applied
with the returned optimizer, either by calling `opt.minimize()` or
`opt.compute_gradients()` followed by `opt.apply_gradients()`.
Gradients should not be computed with tf.gradients or tf.GradientTape.
This is because the returned optimizer will apply loss scaling, and
tf.gradients or tf.GradientTape will not. If you do directly use
tf.gradients or tf.GradientTape, your model may not converge due to
float16 underflow problems. When eager execution is enabled, the mixed precision graph rewrite is only
enabled within tf.function, as outside tf.function, there is no graph. For NVIDIA GPUs with Tensor cores, as a general performance guide, dimensions
(such as batch size, input size, output size, and channel counts)
should be powers of two if under 256, or otherwise divisible by 8 if above
256. For more information, check out the
[NVIDIA Deep Learning Performance Guide](
https://docs.nvidia.com/deeplearning/sdk/dl-performance-guide/index.html). Currently, mixed precision is only enabled on NVIDIA Tensor Core GPUs with
Compute Capability 7.0 and above (Volta, Turing, or newer architectures). The
parts of the graph on CPUs and TPUs are untouched by the graph rewrite. TPU
support is coming soon. CPUs are not supported, as CPUs do not run float16
operations faster than float32 operations.
Parameters
-
intopt - An instance of a
tf.keras.optimizers.Optimizeror atf.train.Optimizer. -
stringloss_scale - Either an int/float, the string `"dynamic"`, or an instance of
a
tf.train.experimental.LossScale. The loss scale to use. It is recommended to keep this as its default value of `"dynamic"`, which will adjust the scaling automatically to prevent `Inf` or `NaN` values.
Returns
-
object - A version of `opt` that will use loss scaling to prevent underflow.
Show Example
model = tf.keras.models.Sequential([
...
]) opt = tf.keras.optimizers.SGD()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt) model.compile(loss="categorical_crossentropy",
optimizer=opt,
metrics=["accuracy"]) model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs)
object enable_mixed_precision_graph_rewrite_dyn(object opt, ImplicitContainer<T> loss_scale)
Enable mixed precision via a graph rewrite. Mixed precision is the use of both float32 and float16 data types when
training a model to improve performance. This is achieved via a graph rewrite
operation and a loss-scale optimizer. Performing arithmetic operations in float16 takes advantage of specialized
processing units, such as NVIDIA Tensor Cores for much higher arithmetic
throughput. However, due to the smaller representable range, performing the
entire training with float16 can result in gradient underflow, that is, small
gradient values becoming zeroes. Instead, performing only select arithmetic
operations in float16 results in higher throughput and decreased training
time when using compatible hardware accelerators while also reducing memory
usage, typically without sacrificing model accuracy. Note: While the mixed precision rewrite changes the datatype of various
layers throughout the model, the same accuracy reached in float32 is
expected. If a `NaN` gradient occurs with dynamic loss scaling, the model
update for that batch is skipped. In this case, the global step count is not
incremented, and the `LossScaleOptimizer` attempts to decrease the loss
scaling value to avoid `NaN` values in subsequent iterations. This approach
has been shown to achieve the same accuracy as float32 and, in most cases,
better training throughput. Example:
For a complete example showing the speed-up on training an image
classification task on CIFAR10, check out this
Colab notebook. Calling `enable_mixed_precision_graph_rewrite(opt)` enables the graph rewrite
operation before computing gradients. The function additionally returns an
`Optimizer`(`opt`) wrapped with a `LossScaleOptimizer`. This prevents
underflow in the float16 tensors during the backward pass. An optimizer of
type The graph rewrite operation changes the `dtype` of certain operations in the
graph from float32 to float16. There are several categories of operations
that are either included or excluded by this rewrite operation. The following
categories of Ops are defined inside corresponding functions under the class
`AutoMixedPrecisionLists` in
auto_mixed_precision_lists.h: * `ClearList`: Ops that do not have numerically significant adverse effects.
E.g. `ArgMax` and `Floor`.
* `WhiteList`: Ops that are considered numerically safe for execution in
float16, and thus are always converted. E.g. `Conv2D`.
* `BlackList`: Ops that are numerically unsafe to execute in float16 and
can negatively affect downstream nodes. E.g. `Softmax`.
* `GrayList`: Ops that are considered numerically safe for execution in
float16 unless downstream from a BlackList Op. E.g. `Add` and `AvgPool`. When this function is used, gradients should only be computed and applied
with the returned optimizer, either by calling `opt.minimize()` or
`opt.compute_gradients()` followed by `opt.apply_gradients()`.
Gradients should not be computed with
tf.train.Optimizer or tf.keras.optimizers.Optimizer must be passed
to this function, which will then be wrapped to use loss scaling. The graph rewrite operation changes the `dtype` of certain operations in the
graph from float32 to float16. There are several categories of operations
that are either included or excluded by this rewrite operation. The following
categories of Ops are defined inside corresponding functions under the class
`AutoMixedPrecisionLists` in
auto_mixed_precision_lists.h: * `ClearList`: Ops that do not have numerically significant adverse effects.
E.g. `ArgMax` and `Floor`.
* `WhiteList`: Ops that are considered numerically safe for execution in
float16, and thus are always converted. E.g. `Conv2D`.
* `BlackList`: Ops that are numerically unsafe to execute in float16 and
can negatively affect downstream nodes. E.g. `Softmax`.
* `GrayList`: Ops that are considered numerically safe for execution in
float16 unless downstream from a BlackList Op. E.g. `Add` and `AvgPool`. When this function is used, gradients should only be computed and applied
with the returned optimizer, either by calling `opt.minimize()` or
`opt.compute_gradients()` followed by `opt.apply_gradients()`.
Gradients should not be computed with tf.gradients or tf.GradientTape.
This is because the returned optimizer will apply loss scaling, and
tf.gradients or tf.GradientTape will not. If you do directly use
tf.gradients or tf.GradientTape, your model may not converge due to
float16 underflow problems. When eager execution is enabled, the mixed precision graph rewrite is only
enabled within tf.function, as outside tf.function, there is no graph. For NVIDIA GPUs with Tensor cores, as a general performance guide, dimensions
(such as batch size, input size, output size, and channel counts)
should be powers of two if under 256, or otherwise divisible by 8 if above
256. For more information, check out the
[NVIDIA Deep Learning Performance Guide](
https://docs.nvidia.com/deeplearning/sdk/dl-performance-guide/index.html). Currently, mixed precision is only enabled on NVIDIA Tensor Core GPUs with
Compute Capability 7.0 and above (Volta, Turing, or newer architectures). The
parts of the graph on CPUs and TPUs are untouched by the graph rewrite. TPU
support is coming soon. CPUs are not supported, as CPUs do not run float16
operations faster than float32 operations.
Parameters
-
objectopt - An instance of a
tf.keras.optimizers.Optimizeror atf.train.Optimizer. -
ImplicitContainer<T>loss_scale - Either an int/float, the string `"dynamic"`, or an instance of
a
tf.train.experimental.LossScale. The loss scale to use. It is recommended to keep this as its default value of `"dynamic"`, which will adjust the scaling automatically to prevent `Inf` or `NaN` values.
Returns
-
object - A version of `opt` that will use loss scaling to prevent underflow.
Show Example
model = tf.keras.models.Sequential([
...
]) opt = tf.keras.optimizers.SGD()
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt) model.compile(loss="categorical_crossentropy",
optimizer=opt,
metrics=["accuracy"]) model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs)